
単体テストのベストプラクティス

タム
2023.07.07
1808
こんにちは。タムです。
タイトルは大きく出てしまいましたが、最近読んだこちらの本が非常に内容が濃く勉強になったため、今回はその紹介記事です。
今まで数多くのテストコードを書いてきましたが、「良いテストコードとはどのようなものか」に関する指針を持っておらず、
実装において悩むケースが多々ありました。
しかし、この本を読むことで、ほぼ全ての疑問が解消されたと思います。
今回そのような、単体テストにまつわる疑問と、それに対する回答という形で、この本の概要を紹介させていただきます。
なお、本記事は本の内容をベースに自分なりの解釈を加えたものであり、必ずしも正確ではない箇所があるかもしれませんので、
予めご了承ください。
大変勉強になるとても良い本でしたので、もっと深く知りたいという方はぜひ本書を手にとっていただければと思います。
また、本記事では特に断らない場合「テスト」とはテストコードを用いた自動テストのことを指します。
どこまでを「単体」とすべきか
古典学派とロンドン学派
これについては2通りの考え方があります。
一つは、「古典学派」と言われるグループの考え方で、一つのテストシナリオを「単体」として扱います。
DBやファイル出力、外部システムへのメッセージ送信などの「共有依存」については、
そのまま使うと他のテストシナリオに影響を与えてしまうため、モックを使用します。
もう一つは、「ロンドン学派」と言われるグループの考え方で、一つのクラスを「単体」として扱います。
こちらは共有依存だけでなく、すべての「協力者オブジェクト」をモックに置き換えることで、
対象のクラスの振る舞いのみに着目します。
本書では、良いテストを構成する4本の柱を示していますが、
ロンドン学派の考え方だとテストコードが実装の詳細に依存しすぎてしまい、4本の柱のうちの一つであり、
かつ最も重要な特性とされる「リファクタリング耐性」を損なってしまうため、
古典学派の考え方を推奨しています。
古典学派のスタイルで記述する単体テストは、DDDで言うところの、最も上位層のドメインサービスやエンティティなどを
対象として扱うテストのことだと自分は理解しています。
ちなみに、4本の柱とは以下のことです。
- リファクタリング耐性
- 退行からの保護
- 迅速なフィードバック
- 保守のしやすさ
このうち迅速なフィードバックとは、テストをした際に結果がすぐに返ってくる、つまり実行時間が短いという性質を示します。
単体テストでは共有依存を使わないため、この性質については必然的にほぼ満たされた状態になります。
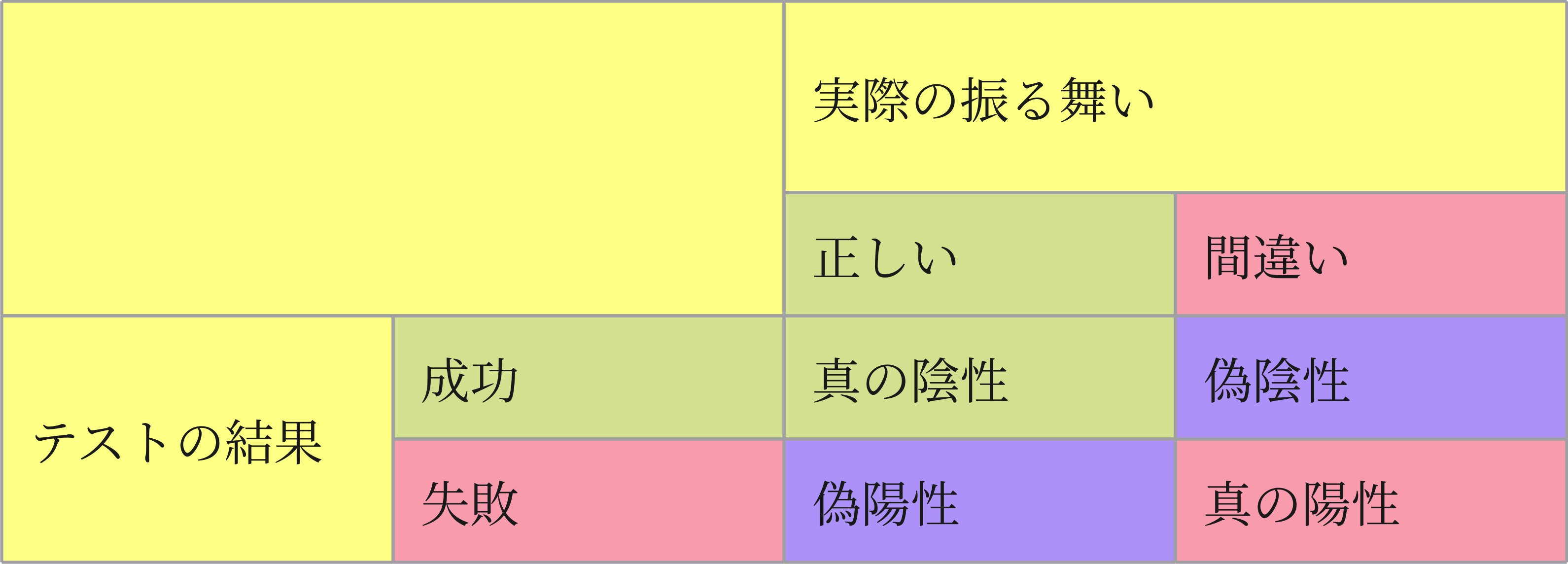
テスト結果と実際の振る舞いの組み合わせパターンは、以下の4パターンがあります。(下図を参照)
- テストが成功し、かつ実際の振る舞いも正しい場合、それは仕様を満たしているということなので真の陰性です。
- 逆に、テストが失敗し、かつ実際の振る舞いも正しくない場合、それはテストが正しくコードの不正を検出しているということなので、真の陽性です。
- テストが成功しているのにもかかわらず、実際の振る舞いが正しくない場合は偽陰性となり、テストがコードの不正を検出できていないということで、多くの場合退行からの保護が十分にできていないということになります。
- テストが失敗しているのにもかかわらず実際の振る舞いが正しい場合は偽陽性となり、テストが壊れた状態を意味します。これはテストが実装の詳細に依存してしまっており、リファクタリングによって依存関係が破壊されるのが原因です。
以上から、良いテストとは偽陰性と偽陽性の可能性を極力排除したものであることがわかります。
またそのためには、4本の柱のうちの2本、つまり退行からの保護とリファクタリング耐性を兼ね備えたテストであることが
必要であることもわかります。
どこまでをテストするのか
テストピラミッド
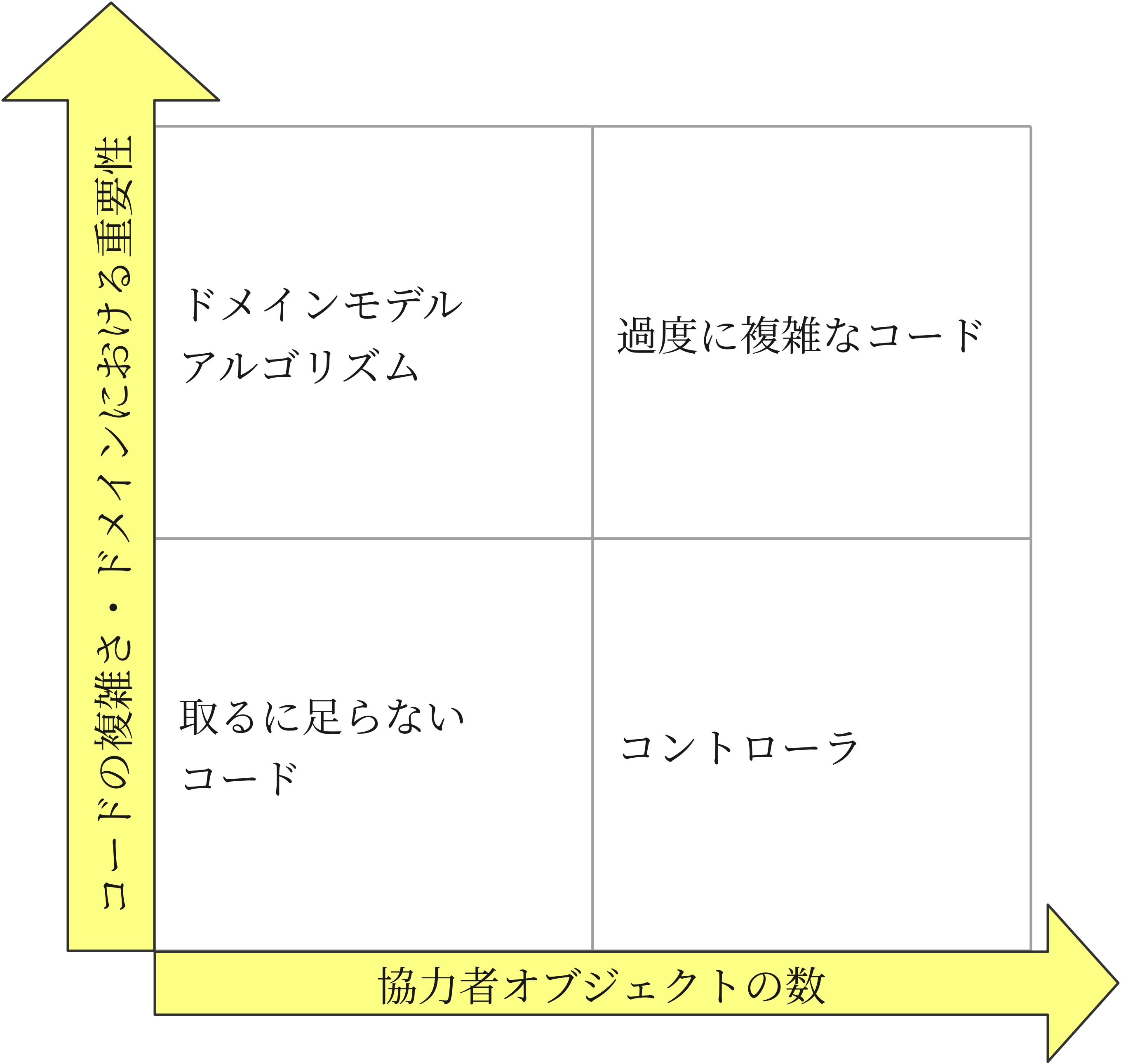
すべてのコードは以下の図の4つのエリアのうちのどこかに位置します。
綺麗にコードの役割分担ができていれば、右上以外のエリアにすべての
コードが属するようになります。
そのようなコードは、テストコードも簡潔に書けるため
4本の柱の一つである、保守のしやすさを備えたテストになります。
このうち、テストに価値をもたらすのは左上と、右下に位置するコードです。
左下に関してはシナリオ内でテストするか、場合によっては全くテストしなくても
問題になることはほとんどありません。
ロジックが単純なため間違える可能性が低く、かつドメインにおける重要性も低いためです。
左上は単体テストで確認し、共有依存はすべてモックに置き換えます。
右下は統合テストで確認し、外部から直接参照できる共有依存はモックに置き換えます。
外部から直接参照できない共有依存の代表はDBであり、インターフェースを
退行から保護する必要性がないためモックに置き換える必要がありません。
その場合、事前準備フェーズで他のテストケースに影響が出ないように状態をリセットする必要があります。
なおテストの種類には他にもE2Eテストがあります。E2Eテストはユーザの視点で行うテストであり、
外部から直接参照できる共有依存も含めて全てのオブジェクトをそのまま扱います。
E2Eテストに関しては外部に影響を与えてしまうことが避けられないため、
個人的にはテストコードとして実装することは困難だと思います。
下の図は「テスト・ピラミッド」と呼ばれる図で、プロジェクトの理想的なテスト構成を表しています。
上に行けば行くほどユーザの視点に近くなります。
下に行けば行くほど横の広がりが大きくなりますが、これはテストの数の多さを表しています。
つまり、単体テスト>統合テスト>E2Eテストの順でテストの数が多くなるべきだ、ということを意味します。
先程も述べたように、単体テストではドメインモデル・アルゴリズムに位置するコードをテスト対象とするため、
ロジックは複雑ですが協力者オブジェクトの数は少ないです。
一方統合テストやE2Eテストの場合、対象はコントローラに位置するコードとなるため、
先ほどとは反対にロジックは単純で協力者オブジェクトの数は多いです。
そのため、単体テストはケース数が多くなり、統合テストやE2Eテストはケース数が少なくなるべきです。
ただし、ドメインのロジックがほとんどないようなアプリケーションの場合、
単体テストとそれ以外のテストは数がほとんど同じになるか、
場合によっては単体テストがないこともありえます。

何をモックにすべきか
共有依存との境界
上記でも触れましたが、モックの使用についての指針は以下です。
- 共有依存ではない依存はモックを使用しない
- 共有依存でも外部に直接公開されない依存(DBなど)はモックを使用しない
モックを使用する場合でも、どのオブジェクトに対してモックするか、が問題になってくると思います。
例えば、API呼び出しを行う場合、
- 使用している言語のAPIライブラリ
- APIライブラリをラップして対象アプリケーションに特化して使いやすくしたオブジェクト
- 2を更にラップして特定のリソースに特化して使いやすくしたオブジェクト(Repositoryのような使い方をする)
というように複数のオブジェクトが関わっていた場合、どのオブジェクトをモック対象とすべきでしょうか?
(以下の図は自分で描いたイメージ図です)

まず、3の場合、上記の中では最も不安定であり、リファクタによってテストが壊れやすいです。
また経由するコード量も最も少ないため、退行からの保護も十分に得られません。
そう考えると1が最も適切なように思えますが、本書では2が最適であると論じられています。
ライブラリは対象アプリケーションだけでなくさまざまなアプリケーションで使われている汎用的なものです。
一方で対象アプリケーションに特化したオブジェクトは当然対象アプリケーションのみで使用しており、
プロジェクトメンバーのみで保守できるため成長をコントロールできます。
ライブラリが変更された場合にも影響が2の層内で収まるようになるので(腐敗防止層)、
この層のインターフェースは保護すべきです。
そのため、2をモックの対象とすることで、3に比べてリファクタリング耐性も得られますし、
インターフェースが変更されればテストが失敗するため、退行からの保護も得られるようになります。
テストコードでロジックを書いてはいけないのか
アンチパターン
細かいトピックですがテストコードあるあるだと思います。
インプットからアウトプットを組み立てるロジックを書いていると
実装をしているような気分になってきて、意味のあるテストになっているのか
不安に思うことがあると思います。
そもそもアウトプットをインプットから組み立てるときの心理としては、
導出できるものは極力導出すべし、というエンジニア脳があると思います。
この場合で言えばアウトプットはインプットから導出できます。
実際、仮にアウトプットを直書きするとインプットを少し変更しただけでテストが壊れるように
なってしまいまうため、エンジニアとしてはある意味正常な脳の働きだと思います。
しかし本書ではむしろ直書きを推奨しています。
インプットからアウトプットを導出するコードはどうしてもプロダクションコードに似てきてしまうためです。
それでも本来であれば退行からの保護は得られるはずですが、
単なるコピペのようなコードであった場合失敗に向き合うのではなく
その場しのぎでテストコードを修正してしまう恐れがあるためとのことです。
個人的には、全てのアウトプットを直書きにすべしとは思いません。
場合によってはコード量が膨大になってしまい、それこそ保守がしづらいコードになってしまう場合があると思うためです。
簡潔に書けるのであれば直書きすべきですし、そうでないならロジックで組み立てるのもありだと思います。
ただその場合も、極力プロダクションコードには似ないようにしたほうがいいと思います。
別解を探すような感覚で、ロジックを実装することになります。
さいごに
まとめ
今回は、テストコードについて掘り下げてみました。
1つの記事にしたら書くことが沢山あってかなり時間がかかってしまいました。
ただそれだけこの本の内容が濃かったということだと思います。
今回具体的なコードを挟まなかったため抽象的な話になってしまいましたが、
本書ではコードも交えながら説明しているためわかりやすいです。
繰り返しになりますが、大変おすすめの本ですので興味を持った方はぜひ読んでいただければと思います。
今回得た知見を実践に活用し、そこで更に得られたフィードバックがあれば、
また別の記事にしようと思います。
最後までご覧いただきありがとうございました。
参考文献
関連記事

コードレビューにおけるフィードバックの分類と心理的安全性の強化
600

新井公貴
2023.06.27


OpenAPIの運用コスト下げたい。
2,533

ケイ
2023.03.15